
A Benchmark of Models for a Call Center Analytics use case
Call centers are one of the main communication channels between customers and companies. The calls to/from the call center contain a gold-mine of valuable information about the customer and its relationship with the companies. At Making Science we are helping customers leverage this value in the business delivering significant ROI on conversational analytics projects.
Before the advent of the modern speech-to-text models, it was almost impossible to process these calls on an industrial scale, since it was a manual process. A very resource-intensive one.
Modern speech-to-text models allow companies to convert call audio records into text, and analyze them to extract valuable insights. With this technology, transcribing a single call can take as little as 4 seconds. However, in-production systems have many challenges:
- PII(personally identifying information) data in call center audios: these calls may contain several pieces of sensitive information (names, addresses, credit card numbers, etc.). If the transcripted calls are stored without PII remotion, this may lead to a potential data leakage.
- Audio records caveats: depending on the call center setup, the records may be stored as mono or stereo audio files. In terms of this particular use case, this has a deep impact. If the audio is stored as a mono file, the recording from the call center operator and the recording from the caller are in the same audio channel; they aren’t separated. In this case, besides the speech-to-text model, an additional diarization step must be included to separate the parts of the audio that belong to each speaker.
From the previous discussion, it is possible to conclude that an in-production audio transcription system must have two core components: the transcription module itself (the one that converts the audio into text) and an anonymization module (to remove all the sensitive data from the transcripts). The following image shows a high-level architecture for this solution.
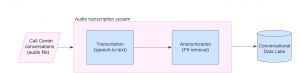 Figure 1. High-level architecture for an audio transcription module.
Figure 1. High-level architecture for an audio transcription module.
Implementing an end-to-end speech-to-text system for call center records is the first step required to extract value for the transcripts by adding other features on top of it. Some of these features are:
- Topic modeling. To know which are the topics discussed in every single conversation.
- Sentiment analysis. To know the client’s sentiment regarding the brand and/or about the outcome of the call.
- Script monitoring. To validate if the call center operator is following the script and analyze the impact of script variations in the communication output.
From audio to text on an industrial scale – the current landscape
To convert audio to text, there are many different speech-to-text models. At Making Science, we compared several models to see which one performs better. The benchmark dataset we used is the Gridspace-Stanford Harper Valley speech dataset, which contains 1446 call center conversations manually transcribed. These recordings are divided into two audio files, one for the call center operator and the other for the caller. Because of that, no diarization is required.
The metric used to evaluate the model’s performance is WER (Word Error Rate). This metric quantifies the mistakes made by the model, taking into account the substitutions, the mistaken insertions, and the deletions done by it. The lower the WER is, the better the model performance is. Since the WER can be greater than one, it isn’t a transcription accuracy percentage. The WER metric is defined as:
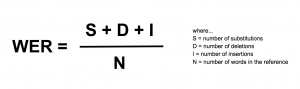 Besides how the WER is, there are also other relevant metrics to evaluate which model is the best one for an industrial-scale application. For example, a few relevant dimensions to take into account for this decision are:
Besides how the WER is, there are also other relevant metrics to evaluate which model is the best one for an industrial-scale application. For example, a few relevant dimensions to take into account for this decision are:
- How much does it cost to translate a minute of audio?
- The latency if your use case requires rapid translation and analytics; how long does it take for the model to transcribe audio?
- Parallelism if your use case has a large number of users waiting for “intelligence”; how many API requests per unit of time can the model provider handle?
- The Privacy; How does the model provider handle our data? Is it possible to deploy a private instance of the model?
For this benchmark, we considered several models from different providers. Also, we tried models that allow the user to deploy a private instance of it and models that are available via a public API. The results we obtained are available in Table 1.
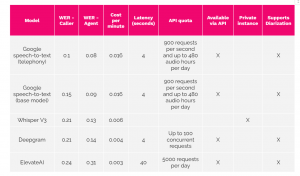 Table 1: benchmark results for speech-to-text task.
Table 1: benchmark results for speech-to-text task.
Key takeaways:
- Google speech-to-text models are the best-performing models at the time of this benchmark(lower WER) for both agent and caller transcriptions.
- In general, the models tend to transcribe better the agent audio than the caller audio. This is an expected behavior because, in general, the audio quality for the agent audio is better.
- Whisper V3 has quite good performance, especially for the caller audio. However, the Whisper model doesn’t support diarization. Because of that, to use it in a production environment when audios can be mono audios, a diarization module should be developed (using, for example, pyannote).
Keeping Pace with Speech-to-Text Advancements
In the fast-paced world of speech-to-text technology, it’s crucial to keep pace with innovation. The performance benchmarks we rely on today may shift as advancements continue.
At Making Science, we understand the importance of adaptability and regularly update our approach to ensure we harness the best tools for unlocking customer insights. Stay informed, stay agile, and stay ahead with us as your analytics ally.




 Cookie configuration
Cookie configuration